AI Vision vs Computer Vision: Are the Curves Crossing?
I was wrong about Computer Vision OCR being dead in 2024, but it appears that's about to change as AI Vision rises.
I thought AI Vision had won out over “old style OCR” when I wrote this piece back in February 2024. It turns out I was wrong; but I’m begining to be right—right now.
Wrong Assumptions
I have a huge knowledge gap, and that is what bit me. I had some significant experience with traditional OCR, many years ago, and it was mostly bad. I then completely skipped the Computer Vision era. I had heard of Computer Vision, but assumed that it was just a rebranding of old, bad, OCR.
My next significant experience with extracting content from images, therefore, came on the abovementioned learning project where I applied OpenAI’s GPT-4V dedicated vision model to extract and structure often-handwritten data from heirloom family recipes. That effort was amazingly successful. That led me to decide, back in early 2024, that OCR (rebranded or not) was dead, long live AI Vision.
Wrong.
Sorry, Guy on Hacker News
That was still my attitude as I kicked off a new AI Vision project earlier this year. The proof of concept phase mostly went well; handwriting recognition worked very well, and the only real extraction problem I had was checkbox detection. I was able to prompt my way to checkbox success, and coming into the production implementation felt quite confident.
Right around this point, I saw a comment on a Hacker News post announcing the new Qwen3-VL next-gen vision model where the writer was saying he had really bad luck using OpenAI vision models on a particular construction form. He went on to say that Qwen3-VL did a great job on it.
I replied with a kind of classic, “you’re holding it wrong” response. Sorry, richardlblair, I now know you were holding it just fine.

My Comeuppance
So we shifted into real implementation on the vision project, and there was a pre-printed form, which customers would print out, then complete by hand. Its primary data section was a matrix of checkboxes, roughly 10 rows by 15 columns.
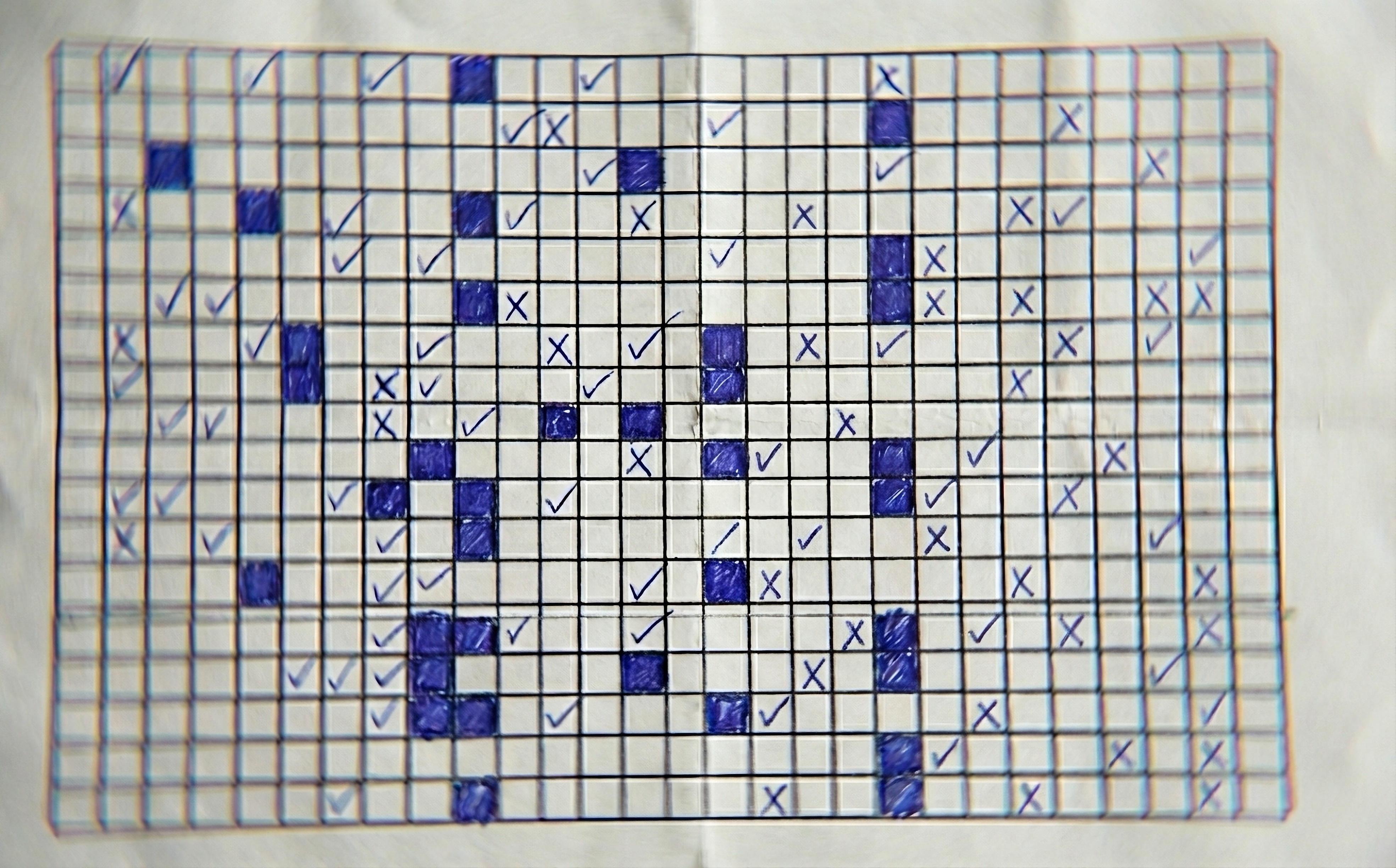
This checkbox matrix proved to be the undoing of AI Vision, at least for this particular task. This was the GPT-5, Gemini Pro 2.5 timeframe, not long ago in human time. None of the mainstream models could reliably detect checkboxes in that dense matrix of 150 cells. This “simple preprinted form” seemed about to derail our implementation.
A Fresh Savior?
That Hacker News article caught my eye for more reasons than one. Qwen3-VL was family of a special-purpose vision model of various sizes and features, freshly released within a few days of my dilemma becoming apparent. We had an OpenRouter path already implemented, so I wired up Qwen3-vl-32B, and after a bit of configuring and prompt tweaking it looked like we had a solution: checkmark detection and selected cell identification was nearly perfect. I was a little nervous that only a few inference providers offered Qwen3-vl models; but hey, it was working extremely well.
Until, one day, it just stopped working. I can’t say with 100% confidence that our code didn’t cause the problem. I can say I’m 98+% sure, however, since we actually rolled the code back to its exact state when checkbox detection last worked reliably—and that code no longer detected checkboxes reliably. If I had to guess, I’d say the model was prone to entering a corrupt state, losing its mind in effect.
The downside of working with a bleeding-edge model, served by 3rd party inference providers, over OpenRouter and its extra layer of API translation—who ya gonna call? Ghostbusters would have been a better answer by far. If your OpenAI or Anthropic model has issues, at the very least you know they have people closely following the health of the model and deeply concerned if anything looks broken. With the long, weak chain of custody in our OpenRouter configuration? I’m not sure anyone was paying attention at any of the parties. I did post a ticket to OpenRouter, with the only visible result being that they shut down the endpoint I was using, completely and without notice.
We switched to a larger Qwen3-VL model and continued trying to make things work, to no avail.
In fairness, based on my genuine early success with the model, I believe that a bugfixed, properly configured, correctly operated Qwen3 VL model would be capable of checkmark detection and selected cell identification. Unfortunately, our early-days experience was more the “buggy and unreliable” variety.
Computer Vision? I Don’t Wanna …
My next step was actually to quickly prototype a classical Python CV solution using readily-available CV libraries. This immediately exposed a world of hurt with no clear escape; our use case wasn’t 100,000 forms of the exact same size and shape, and it wasn’t clear how to even get the CV engine focused on the right part of the form, when that part would almost never be in the same place from one image to the next. I know, that’s a solved problem, with a few added steps in the CV pipeline. I think my insticts were correct, though—classical Python CV was never going to be a scope-effective solution on this project.
My partner on the project suggested we check out Amazon Textract. I was skeptical, of course, certainly not any less so based on my classical CV attempt. But AWS has a nice UI for quickly testing Textract, and it didn’t take long to be won over, as form after inconsistent form came through with good handwriting extraction and virtually perfect checkmark detection.
Textract is the gap in my knowledge, the thing I didn’t know existed: a machine learning augmented CV service. It applies ML to overcome hard CV problems (like checkbox detection!) and reduce the learning curve and implementation pain. In caveman speak, the flow is:

And there you go, done! It’s CVML, very well executed.
But ML Is Not AI …
Following the tremendous relief of finding a reliable form parsing solution, I began to notice that Textract, while it solved our most crucial problem, was in other areas less effective than AI. Textract’s ML was powerful but it was not a language model and was clearly very dumb about language. AI would continually surprise and delight, realizing that handwriting that looks like “Co” was actually part of an address, and that the more correct extraction would be “CO” the state abbreviation. Or see a series of handwritten numbers “3427” … “28” … “29” … “30” and realize these should be extracted as 3427, 3428, 3429, 3430. Many small differences but they added up.
We decided to try taking Textract’s raw form and table data, and passing it through the AI with a simple prompt, basically “refine this.” Magical! Hugely better than Textract alone, without even seeing the source image.
The Lines Are Crossing Right Now
As I described above, if it weren’t for bugs and crappy inference operations (or my own incompetence), I believe that Qwen3 VL was a workable AI Vision solution for our use case. And it would have given us the benefits of Textract, plus the benefits of AI, all in one (unbelievably inexpensive) AI call.
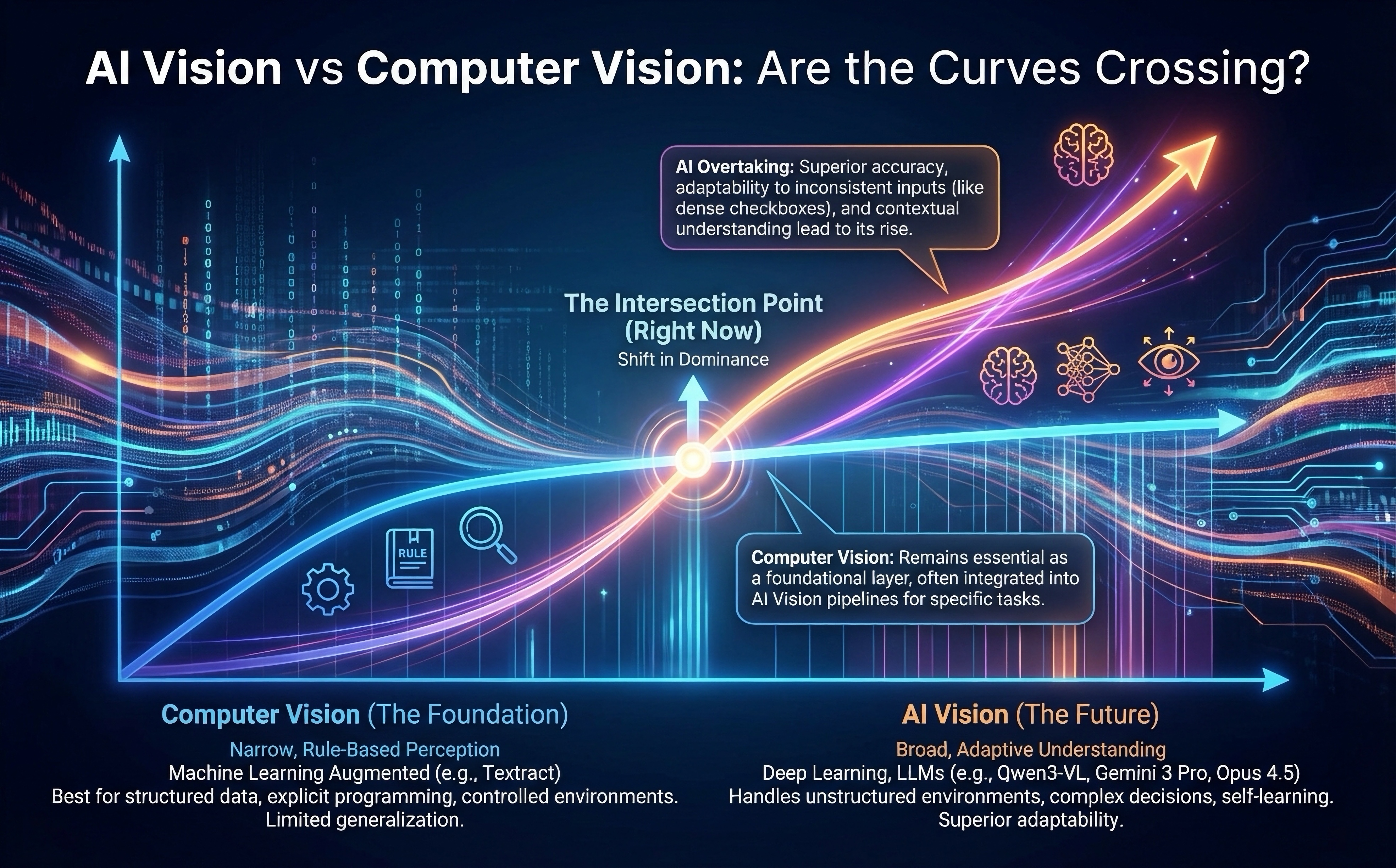
Furthermore, even after we had Textract in place, I kept a close eye on new models, of which we have many these days! In limited testing on the dense checkbox matrix form, it appears that Gemini 3 Pro Preview performed almost as well as Qwen3 VL, and that’s with no parameter tuning, just running Preview through one of Google’s playground UIs. Surprisingly, so did Gemini Flash Latest. YMMV – limited testing here.
Most recently, I’ve been using Anthropic’s new Opus 4.5 model in Claude Code. As I worked to improve extraction errors we were seeing with GPT-5.1 as the vision model on simpler plastic-bag-printed forms, I noticed that Code was able to parse checkboxes very accurately when I gave it example images during our development process. Then I remembered that improved vision capabilities were mentioned in the Opus 4.5 announcement.
So I wired up the (new beta) Anthropic API and turned Opus 4.5 loose on our bag-form images. Bingo! We’re now at 100% bag-form checkbox detection on our golden dataset images, a large improvement over GPT-5.1. Again, YMMV; we definitely didn’t have the time to test every configuration thoroughly.
In any case, though, to me it is clear that the AI Vision line is right this second about to eclipse the ML-augmented CV line for use cases like ours, where we have comparatively inconsistent and unpredictable inputs, but also need to precisely “see” image features such as those pesky checkboxes.