Chroma: RAG is Dead; Long Live Context Engineering
Jeff Huber explores how Chroma is changing the conversation away from RAG to context engineering
If RAG (Retrieval Augmented Generation) is dead, then what’s alive? What’s the right way of thinking about and exposing company knowledge through AIs? This episode of the Latent Space podcast, featuring Chroma CEO and cofounder Jeff Huber, has compelling answers. Highly recommended listen (or watch here).
What & Who is Chroma?
Chroma is an open-source embedding database purpose-built for LLM applications. The company was founded in 2022 by Jeff Huber (CEO) and Anton Troynikov.
Core Purpose
Chroma lets developers store embeddings alongside metadata and associated text, then run fast similarity search with filtering to ground LLM outputs in relevant, verifiable context—reducing hallucinations and improving answer quality.
Core Features
- Vector similarity search over collections
- Metadata filtering for precise retrieval
- Persistent storage for vectors, metadata, and associated text
- Official client libraries: Python and JavaScript/TypeScript (first‑party); additional clients for Ruby, Java, Go, C#, Elixir, and Rust
- Embedding-agnostic: works with text and other modalities via embeddings
Extended Features and Commercial Offerings
Beyond the core open-source capabilities, Chroma offers Chroma Distributed–—an open-source, distributed version built in Rust that enables multi-node deployments for scalability and high-throughput requirements. For teams seeking a fully managed solution, Chroma Cloud provides a serverless, distributed architecture that abstracts infrastructure complexity while supporting deployment across major cloud platforms (AWS, GCP, Azure).
Snip: RAG => Context Engineering
Huber detests the term “RAG” and his opinions on the topic helped convince Swyx to remove the RAG track from the AI Engineer World’s Fair event in June.

He describes in this snip what I believe is a far better framing of the core issue and solution—context engineering.
Snip: Context Rot
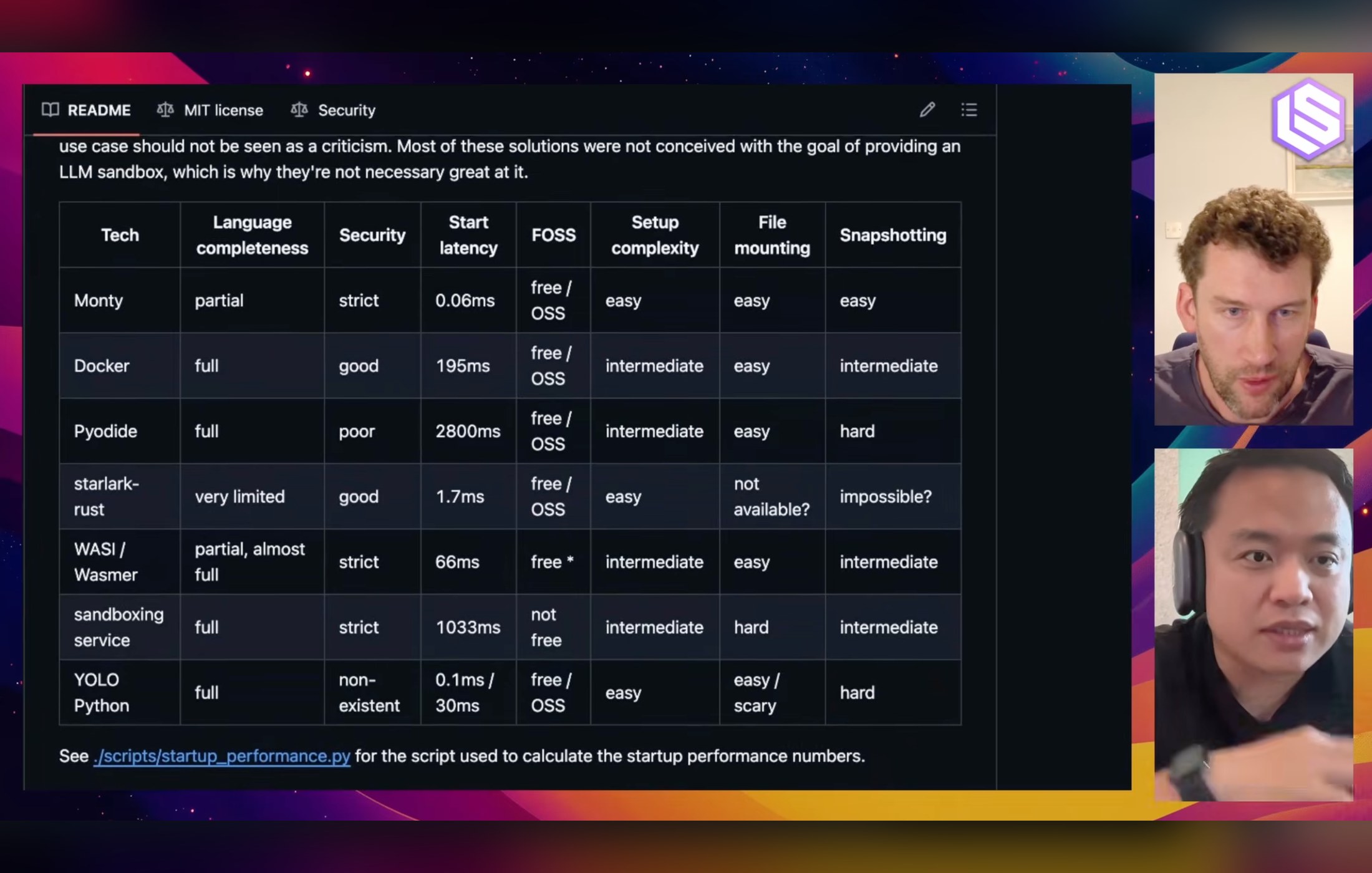
Model builders like OpenAI, Anthropic, and Google DeepMind keep announcing increasingly large context windows, to 1M tokens and beyond. And with contexts getting larger and larger, who needs a retrieval solution like Chroma?

But there’s a dirty little secret known mainly among researchers—context rot. When a large context gets operated on repeatedly, for example in multi-turn agent interactions, the context “rots,” and the model effectively loses its mind, most seriously the failure to follow clearly-stated instructions. Chroma researched this problem carefully, and in this snip, Huber describes what they discovered.
Snip: Context Chunk Selection and LLM Re-ranking
Huber and Chroma definitely have their finger on the pulse of “latest context engineering tips and tricks” …

In this snip he shares emerging practices around getting from 1M or 100K down to 30 using LLM brute-forcing.
Snip: Code Embeddings
There’s an ongoing debate around whether, in the AI coding world, does using embeddings via a vector database like Chroma make sense, versus simpler, very-widely-used approaches like plain old grepping.

Here Huber addresses this question; the answer, in short, is yes, if you want to get the full 100% rather than settling for 80%.
Snip: Evals and Golden Datasets
If you want your AI-driven knowledge access application to start good and stay good, constant evaluation of whether queries are returning the right answers is table stakes. And accurate evals require “golden datasets” with human-curated sets of “this query should serve up these documents.”

In this snip, Huber talks through just how non-painful the process of creating a golden dataset can be.